Data lake technology is the cornerstone of modern data management, offering a centralized repository for all types of data. At pioneer-technology.com, we are dedicated to demystifying this technology, showcasing its potential to revolutionize data analytics, and providing you with the insights needed to leverage its power. Explore how data lake technology can transform your business by enabling advanced analytics, improving decision-making, and fostering data-driven innovation, driving success in today’s dynamic business environment.
1. What Exactly Is Data Lake Technology?
Data lake technology is a data storage architecture that holds vast amounts of raw data in its native format, including structured, semi-structured, and unstructured data. According to research from Gartner, by 2025, data lakes will support 80% of enterprise data analytics initiatives, solidifying their role as essential components for organizations striving to be data-driven. Data lake technology acts as a single, centralized repository where data can be stored as-is, without the need to first structure it. This approach allows organizations to ingest data quickly and efficiently, making it accessible for a variety of analytical and operational use cases.
1.1. Diving Deeper into the Definition of Data Lake Technology
Data lake technology is more than just a storage solution; it’s a comprehensive ecosystem designed to support the end-to-end data lifecycle. It involves the ingestion, storage, processing, and analysis of data from various sources, all within a unified environment. Data lake technology enables organizations to break down data silos and create a single source of truth for their data assets.
1.2. Key Components of a Data Lake
To fully understand what data lake technology entails, it’s important to recognize its key components:
- Data Ingestion: The process of collecting data from various sources, such as databases, applications, IoT devices, and external APIs.
- Storage: Scalable and cost-effective storage solutions like Hadoop Distributed File System (HDFS) or cloud-based object storage (e.g., Amazon S3, Azure Blob Storage).
- Data Processing: Tools and frameworks for transforming and preparing data for analysis, such as Apache Spark, Apache Hadoop, and cloud-based data processing services.
- Data Governance: Policies and processes for ensuring data quality, security, and compliance.
- Analytics: A range of analytical tools and techniques, including SQL queries, data mining, machine learning, and visualization.
1.3. Exploring Data Lake Architecture
The architecture of a data lake is designed to handle large volumes of data with flexibility and scalability. A typical data lake architecture consists of several layers:
- Ingestion Layer: Responsible for collecting data from various sources and landing it in the data lake.
- Storage Layer: Provides scalable and cost-effective storage for raw data.
- Processing Layer: Transforms and prepares data for analysis.
- Consumption Layer: Provides access to data for various analytical and operational use cases.
1.4. Benefits of Using Data Lake Technology
Data lake technology offers numerous benefits for organizations looking to harness the power of their data:
- Flexibility: Support for all types of data, structured, semi-structured, and unstructured.
- Scalability: Ability to handle large volumes of data at low cost.
- Agility: Faster time to insight by enabling quick and easy access to data.
- Innovation: Support for advanced analytics and machine learning, driving innovation and competitive advantage.
2. What Are the Core Principles Behind Data Lake Technology?
The core principles of data lake technology revolve around flexibility, scalability, and accessibility, which enable organizations to derive maximum value from their data assets. According to a 2024 report by McKinsey, companies that embrace data lake technology are 23 times more likely to acquire customers and 6 times more likely to retain those customers.
2.1. Flexibility in Data Handling
Data lakes are designed to accommodate a wide variety of data types, from structured data stored in relational databases to unstructured data such as text, images, and videos. This flexibility is crucial for organizations dealing with diverse data sources and evolving data requirements.
- Schema-on-Read: Data lakes employ a “schema-on-read” approach, meaning that the structure and format of the data are not defined until it is accessed for analysis. This allows data to be ingested quickly without upfront transformation.
- Support for Diverse Data Formats: Data lakes can store data in various formats, including JSON, XML, CSV, Parquet, and ORC, providing flexibility in how data is ingested and processed.
- Adaptability to Changing Data Needs: Data lakes can easily adapt to changing data needs, allowing organizations to ingest new data sources and modify existing data without disrupting the overall architecture.
2.2. Scalability for Big Data
Scalability is a fundamental principle of data lake technology. Data lakes are designed to handle massive volumes of data, often measured in terabytes or petabytes, and can scale horizontally to accommodate growing data needs.
- Distributed Storage: Data lakes typically use distributed storage systems like Hadoop Distributed File System (HDFS) or cloud-based object storage (e.g., Amazon S3, Azure Blob Storage) to store data across multiple nodes.
- Parallel Processing: Data lakes leverage parallel processing frameworks like Apache Spark and Apache Hadoop to process large datasets quickly and efficiently.
- Cost-Effectiveness: Data lakes offer cost-effective storage and processing solutions, allowing organizations to store and analyze large volumes of data without incurring excessive costs.
2.3. Accessibility for Data-Driven Insights
Data lakes are designed to make data easily accessible to a wide range of users, from data scientists and analysts to business users. This accessibility is crucial for fostering a data-driven culture and enabling informed decision-making.
- Unified Data Repository: Data lakes provide a single, centralized repository for all of an organization’s data assets, eliminating data silos and making it easier to discover and access data.
- Self-Service Analytics: Data lakes support self-service analytics, allowing users to explore data and generate insights without relying on IT or data engineering teams.
- Integration with Analytics Tools: Data lakes integrate with a wide range of analytics tools, including SQL query engines, data mining tools, machine learning platforms, and visualization software.
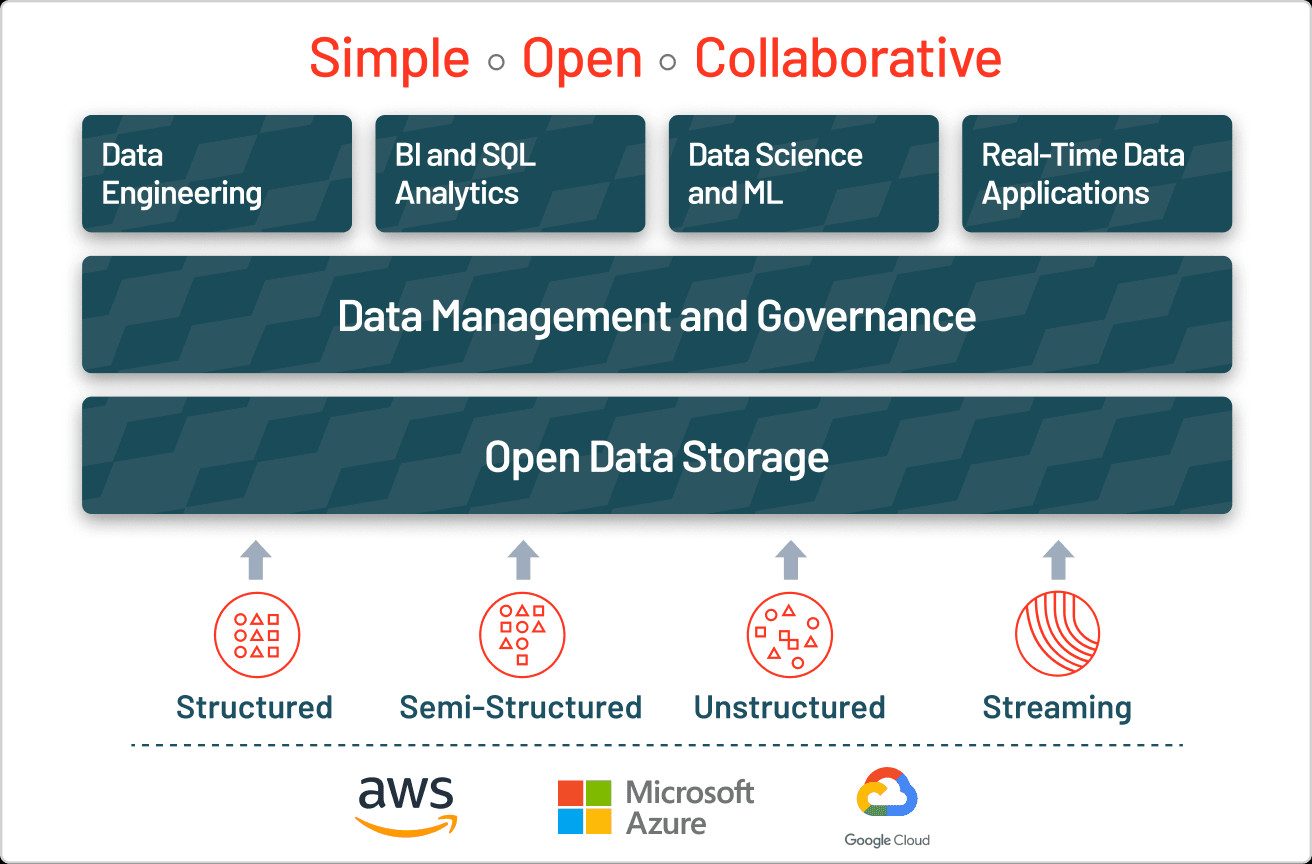 Data Lake Architecture
Data Lake Architecture
Alt: Data lake architecture showcasing ingestion, storage, processing, and consumption layers, emphasizing integration with various analytics tools for streamlined data analysis.
2.4. Data Governance and Security
While flexibility, scalability, and accessibility are key principles, data governance and security are equally important. Data lakes must implement robust data governance policies and security measures to ensure data quality, compliance, and protection against unauthorized access.
- Data Cataloging: Data lakes use data catalogs to track and manage metadata, making it easier to discover and understand data assets.
- Data Quality Monitoring: Data lakes implement data quality monitoring processes to ensure that data is accurate, complete, and consistent.
- Access Control: Data lakes use access control mechanisms to restrict access to sensitive data and prevent unauthorized users from accessing or modifying data.
3. Where Does Data Lake Technology Fit in the Big Data Landscape?
Data lake technology plays a crucial role in the big data landscape by providing a scalable and flexible storage solution for handling the volume, velocity, and variety of big data. A 2023 survey by Statista found that 67% of companies consider data lakes essential for their big data strategies, highlighting their importance in managing and analyzing large datasets.
3.1. Addressing the Challenges of Big Data
Big data presents several challenges for organizations, including:
- Volume: The sheer amount of data generated by modern businesses can overwhelm traditional data storage and processing systems.
- Velocity: The speed at which data is generated and needs to be processed is increasing rapidly.
- Variety: Data comes in many different formats and from a wide range of sources, making it difficult to integrate and analyze.
3.2. How Data Lakes Enable Big Data Solutions
Data lake technology addresses these challenges by providing a scalable and flexible platform for storing and processing big data.
- Scalable Storage: Data lakes can scale horizontally to accommodate massive volumes of data at low cost.
- High-Speed Ingestion: Data lakes can ingest data quickly from a wide range of sources, including streaming data.
- Support for Diverse Data Types: Data lakes can store data in its native format, regardless of whether it is structured, semi-structured, or unstructured.
3.3. Data Lakes vs. Data Warehouses
It’s important to distinguish data lakes from data warehouses, which are another common type of data storage solution.
| Feature | Data Lake | Data Warehouse |
|---|---|---|
| Data Types | Structured, semi-structured, and unstructured | Primarily structured |
| Schema | Schema-on-read | Schema-on-write |
| Scalability | Highly scalable and cost-effective | Less scalable and more expensive |
| Data Transformation | Minimal upfront transformation | Extensive upfront transformation |
| Use Cases | Data exploration, data science, machine learning | Reporting, business intelligence, data analytics |
3.4. Complementary Technologies
Data lakes often work in conjunction with other big data technologies, such as:
- Apache Hadoop: A distributed processing framework for handling large datasets.
- Apache Spark: A fast and versatile data processing engine.
- Apache Kafka: A distributed streaming platform for real-time data ingestion.
- Cloud-Based Data Services: Services like Amazon EMR, Azure HDInsight, and Google Cloud Dataproc provide managed Hadoop and Spark environments.
4. What Are the Practical Applications of Data Lake Technology?
The practical applications of data lake technology are vast and varied, spanning industries from healthcare to finance to retail. According to a 2022 report by Forbes, 90% of the world’s data was created in the last two years, underscoring the need for efficient data management solutions like data lakes to derive actionable insights.
4.1. Use Cases Across Industries
- Healthcare: Improving patient care by analyzing electronic health records, medical imaging data, and genomic data.
- Finance: Detecting fraud, managing risk, and personalizing financial services by analyzing transactional data, market data, and customer data.
- Retail: Optimizing inventory management, personalizing marketing campaigns, and improving customer experience by analyzing sales data, customer data, and social media data.
- Manufacturing: Improving operational efficiency, predicting equipment failures, and optimizing supply chain management by analyzing sensor data, machine data, and supply chain data.
- Telecommunications: Enhancing network performance, reducing customer churn, and personalizing services by analyzing network data, customer data, and usage data.
4.2. Data Lake Technology in Healthcare
In healthcare, data lake technology is transforming the way medical professionals deliver care. By aggregating data from disparate sources like electronic health records, imaging systems, and wearable devices, data lakes provide a comprehensive view of patient health.
- Personalized Medicine: Data lakes enable personalized medicine by analyzing patient-specific data to identify optimal treatment plans and predict health outcomes.
- Predictive Analytics: Data lakes can be used to predict disease outbreaks, identify high-risk patients, and optimize resource allocation.
- Clinical Research: Data lakes facilitate clinical research by providing a centralized repository for clinical trial data and enabling researchers to analyze large datasets quickly and efficiently.
4.3. Data Lake Technology in Finance
In the finance industry, data lake technology is helping financial institutions to detect fraud, manage risk, and personalize services.
- Fraud Detection: Data lakes can be used to detect fraudulent transactions by analyzing patterns and anomalies in transactional data.
- Risk Management: Data lakes enable risk managers to assess and manage risk more effectively by providing a comprehensive view of risk exposures.
- Personalized Banking: Data lakes can be used to personalize banking services by analyzing customer data to identify individual needs and preferences.
4.4. Data Lake Technology in Retail
In the retail industry, data lake technology is helping retailers to optimize inventory management, personalize marketing campaigns, and improve customer experience.
- Inventory Optimization: Data lakes can be used to optimize inventory levels by analyzing sales data, supply chain data, and market trends.
- Personalized Marketing: Data lakes enable retailers to personalize marketing campaigns by analyzing customer data to identify individual preferences and behaviors.
- Customer Experience: Data lakes can be used to improve customer experience by analyzing customer feedback, social media data, and website analytics.
5. How Does Data Lake Technology Enhance Machine Learning Capabilities?
Data lake technology is a game-changer for machine learning (ML), providing the ideal environment for developing and deploying sophisticated ML models. According to a 2023 study by O’Reilly, organizations using data lakes for machine learning report a 30% improvement in model accuracy and a 20% reduction in model development time.
5.1. Providing a Centralized Data Repository
Data lakes serve as a centralized repository for all the data needed for machine learning, including structured, semi-structured, and unstructured data. This eliminates the need to move data between different systems, simplifying the ML development process.
- Data Variety: Data lakes can store a wide variety of data types, enabling ML models to learn from diverse sources of information.
- Data Volume: Data lakes can handle large volumes of data, allowing ML models to be trained on more comprehensive datasets.
- Data Velocity: Data lakes can ingest data quickly, enabling ML models to be updated with the latest information.
5.2. Simplifying Data Preparation
Data preparation is a critical step in the ML process, and data lakes provide a range of tools and frameworks for simplifying this task.
- Data Cleaning: Data lakes offer tools for cleaning and transforming data, such as data quality monitoring and data profiling.
- Data Integration: Data lakes can integrate data from different sources, providing a unified view of the data for ML models.
- Feature Engineering: Data lakes provide tools for creating new features from existing data, which can improve the accuracy of ML models.
5.3. Enabling Scalable Model Training
Data lakes provide the scalable infrastructure needed for training ML models on large datasets.
- Distributed Computing: Data lakes leverage distributed computing frameworks like Apache Spark and Apache Hadoop to train ML models in parallel.
- GPU Acceleration: Data lakes can be configured with GPU acceleration to speed up the training of deep learning models.
- Cloud-Based ML Services: Data lakes can integrate with cloud-based ML services like Amazon SageMaker, Azure Machine Learning, and Google Cloud AI Platform, providing access to a range of pre-built ML algorithms and tools.
5.4. Supporting Model Deployment and Monitoring
Data lakes support the deployment and monitoring of ML models, ensuring that they continue to perform well over time.
- Model Deployment: Data lakes can be used to deploy ML models to production environments, making them accessible to end-users.
- Model Monitoring: Data lakes offer tools for monitoring the performance of ML models, such as accuracy, precision, and recall.
- Model Retraining: Data lakes can be used to retrain ML models with new data, ensuring that they stay up-to-date and accurate.
6. What Are the Key Technologies Used in Data Lake Implementation?
Implementing a data lake involves a combination of technologies for data ingestion, storage, processing, and analysis. A 2024 report by Research and Markets estimates the global data lake market will reach $29.9 billion by 2027, driven by the adoption of key technologies that enable efficient data management and analytics.
6.1. Data Ingestion Tools
- Apache Kafka: A distributed streaming platform for real-time data ingestion.
- Apache Flume: A distributed data collection service for streaming data.
- Apache NiFi: A dataflow automation system for collecting, routing, and transforming data.
- AWS Kinesis: A scalable and durable real-time data streaming service.
- Azure Event Hubs: A highly scalable event ingestion service.
- Google Cloud Pub/Sub: A messaging service for exchanging event data.
6.2. Data Storage Solutions
- Hadoop Distributed File System (HDFS): A distributed file system for storing large datasets.
- Amazon S3: A scalable object storage service.
- Azure Blob Storage: A scalable object storage service.
- Google Cloud Storage: A scalable object storage service.
6.3. Data Processing Frameworks
- Apache Hadoop: A distributed processing framework for handling large datasets.
- Apache Spark: A fast and versatile data processing engine.
- Apache Flink: A stream processing framework for real-time data analytics.
- AWS EMR: A managed Hadoop and Spark environment.
- Azure HDInsight: A managed Hadoop and Spark environment.
- Google Cloud Dataproc: A managed Hadoop and Spark environment.
6.4. Data Analytics Tools
- SQL Query Engines: Apache Hive, Apache Impala, Presto.
- Data Mining Tools: R, Python, Weka.
- Machine Learning Platforms: TensorFlow, PyTorch, scikit-learn.
- Visualization Software: Tableau, Power BI, Qlik.
7. What Are the Challenges Associated With Data Lake Technology?
Despite its many benefits, data lake technology also presents several challenges that organizations must address to ensure success. A 2023 survey by Dresner Advisory Services found that data quality and data governance are the top challenges faced by organizations implementing data lakes.
7.1. Data Quality Issues
- Data Inconsistency: Data from different sources may be inconsistent or contradictory.
- Data Incompleteness: Data may be missing or incomplete.
- Data Inaccuracy: Data may be inaccurate or outdated.
- Data Duplication: Data may be duplicated across multiple sources.
7.2. Data Governance and Security Concerns
- Lack of Data Governance Policies: Organizations may lack clear policies for managing data quality, security, and compliance.
- Data Access Control: It can be difficult to control access to sensitive data and prevent unauthorized users from accessing or modifying data.
- Data Security Breaches: Data lakes can be vulnerable to security breaches if not properly secured.
- Compliance Requirements: Data lakes must comply with various regulatory requirements, such as GDPR and HIPAA.
7.3. Complexity in Data Processing
- Data Integration: Integrating data from different sources can be complex and time-consuming.
- Data Transformation: Transforming data into a format suitable for analysis can be challenging.
- Performance Optimization: Optimizing the performance of data processing jobs can be difficult.
7.4. Skill Gap and Resource Constraints
- Lack of Skilled Professionals: Organizations may lack the skilled professionals needed to implement and manage data lakes.
- Resource Constraints: Organizations may face resource constraints in terms of budget, time, and personnel.
8. How Can Organizations Overcome Data Lake Challenges?
To overcome the challenges associated with data lake technology, organizations should adopt best practices for data governance, data quality, and data security. According to a 2022 report by TDWI, organizations that implement strong data governance practices are 40% more likely to achieve success with their data lake initiatives.
8.1. Implementing Data Governance Policies
- Define Clear Roles and Responsibilities: Assign clear roles and responsibilities for data governance, including data owners, data stewards, and data custodians.
- Establish Data Quality Standards: Define data quality standards and implement processes for monitoring and improving data quality.
- Implement Data Access Controls: Implement data access controls to restrict access to sensitive data and prevent unauthorized users from accessing or modifying data.
- Establish Data Retention Policies: Define data retention policies for determining how long data should be retained and when it should be archived or deleted.
8.2. Ensuring Data Quality
- Data Profiling: Use data profiling tools to identify data quality issues, such as data inconsistency, incompleteness, and inaccuracy.
- Data Cleansing: Implement data cleansing processes to correct data quality issues.
- Data Validation: Implement data validation rules to ensure that data meets predefined standards.
- Data Monitoring: Monitor data quality on an ongoing basis to detect and address data quality issues promptly.
8.3. Enhancing Data Security
- Data Encryption: Encrypt data at rest and in transit to protect it from unauthorized access.
- Access Control: Implement access control mechanisms to restrict access to sensitive data.
- Security Auditing: Conduct regular security audits to identify and address security vulnerabilities.
- Compliance Monitoring: Monitor data lakes to ensure compliance with regulatory requirements.
8.4. Addressing Skill Gap and Resource Constraints
- Training and Education: Provide training and education to employees to develop the skills needed to implement and manage data lakes.
- Outsourcing: Consider outsourcing data lake implementation and management to specialized service providers.
- Cloud-Based Solutions: Leverage cloud-based data lake solutions to reduce the need for in-house infrastructure and expertise.
9. What Is the Future of Data Lake Technology?
The future of data lake technology is bright, with ongoing innovations and advancements driving its evolution. According to a 2024 forecast by IDC, the data lake market will continue to grow at a compound annual growth rate (CAGR) of 22% through 2028, driven by the increasing adoption of cloud-based data lakes and the growing demand for real-time analytics.
9.1. Convergence of Data Lakes and Data Warehouses
- Lakehouse Architecture: The emergence of lakehouse architecture, which combines the best features of data lakes and data warehouses, is transforming the data management landscape.
- Unified Data Platform: Lakehouse architecture provides a unified data platform for storing, processing, and analyzing all types of data, both structured and unstructured.
- Improved Data Governance: Lakehouse architecture improves data governance by providing a centralized and consistent approach to data management.
9.2. Integration With Artificial Intelligence (AI)
- AI-Powered Data Lakes: Data lakes are becoming increasingly integrated with AI technologies, enabling organizations to automate data management tasks and generate insights more quickly.
- Automated Data Discovery: AI-powered data lakes can automatically discover and classify data assets, making it easier to find and understand data.
- Intelligent Data Quality Monitoring: AI-powered data lakes can automatically monitor data quality and identify data quality issues, reducing the need for manual intervention.
9.3. Real-Time Data Analytics
- Streaming Data Ingestion: Data lakes are becoming more adept at ingesting and processing streaming data, enabling organizations to analyze data in real-time.
- Real-Time Data Processing: Data lakes are leveraging stream processing frameworks like Apache Flink and Apache Kafka Streams to process data in real-time.
- Real-Time Data Visualization: Data lakes are integrating with real-time data visualization tools, allowing users to monitor data and generate insights in real-time.
9.4. Cloud-Native Data Lakes
- Cloud Adoption: The increasing adoption of cloud computing is driving the growth of cloud-native data lakes.
- Scalability and Cost-Effectiveness: Cloud-native data lakes offer scalability and cost-effectiveness, allowing organizations to store and process large volumes of data at low cost.
- Managed Services: Cloud providers offer managed data lake services, such as Amazon S3, Azure Data Lake Storage, and Google Cloud Storage, reducing the need for in-house infrastructure and expertise.
10. How Can Pioneer-Technology.Com Help You Navigate Data Lake Technology?
At pioneer-technology.com, we understand the complexities of data lake technology and are committed to providing you with the resources and insights you need to succeed. Our platform offers a wealth of information on data lake technology, from introductory guides to advanced tutorials.
10.1. Expert Insights and Analysis
Our team of technology experts provides in-depth analysis and insights on the latest trends and developments in data lake technology. We help you stay ahead of the curve by providing clear, concise, and actionable information.
10.2. Comprehensive Guides and Tutorials
We offer a range of comprehensive guides and tutorials that cover all aspects of data lake technology, from data ingestion and storage to data processing and analytics. Our guides are designed to help you learn at your own pace and master the skills you need to build and manage a successful data lake.
10.3. Case Studies and Real-World Examples
We showcase real-world examples of how organizations are using data lake technology to solve business problems and drive innovation. Our case studies provide valuable insights into the practical applications of data lake technology across various industries.
10.4. Community and Support
Join our community of data lake enthusiasts and connect with other professionals who are passionate about data. Our community provides a forum for sharing knowledge, asking questions, and getting support from experts.
Ready to explore the world of data lake technology and unlock the potential of your data? Visit pioneer-technology.com today to discover the latest insights, resources, and solutions. Contact us at Address: 450 Serra Mall, Stanford, CA 94305, United States. Phone: +1 (650) 723-2300 or visit our Website: pioneer-technology.com to learn more and take the first step towards data-driven success. Explore our articles, discover innovative products, and stay ahead of the curve with pioneer-technology.com.
FAQ: Understanding Data Lake Technology
1. What is the primary difference between a data lake and a data warehouse?
A data lake stores all types of data in its native format, using a schema-on-read approach, while a data warehouse stores structured data with a predefined schema-on-write.
2. How does data lake technology handle unstructured data?
Data lake technology stores unstructured data in its native format, such as text, images, and videos, without requiring upfront transformation.
3. What are the key benefits of using data lake technology for machine learning?
Data lake technology provides a centralized repository for all the data needed for machine learning, simplifies data preparation, and enables scalable model training.
4. What are the main challenges associated with data lake implementation?
The main challenges include data quality issues, data governance and security concerns, complexity in data processing, and skill gap and resource constraints.
5. How can organizations ensure data quality in a data lake?
Organizations can ensure data quality by implementing data governance policies, data profiling, data cleansing, data validation, and data monitoring.
6. What are the key technologies used in data lake implementation?
Key technologies include data ingestion tools (e.g., Apache Kafka), data storage solutions (e.g., Amazon S3), data processing frameworks (e.g., Apache Spark), and data analytics tools (e.g., Tableau).
7. How does data lake technology support real-time data analytics?
Data lake technology supports real-time data analytics by ingesting and processing streaming data using stream processing frameworks like Apache Flink and Apache Kafka Streams.
8. What is the role of data governance in data lake technology?
Data governance ensures data quality, security, and compliance in data lakes by defining clear roles and responsibilities, establishing data quality standards, and implementing data access controls.
9. How does the lakehouse architecture combine the benefits of data lakes and data warehouses?
The lakehouse architecture provides a unified data platform for storing, processing, and analyzing all types of data, both structured and unstructured, while improving data governance and reducing data silos.
10. What is the future of data lake technology in the context of AI and machine learning?
The future of data lake technology involves increased integration with AI technologies, enabling automated data discovery, intelligent data quality monitoring, and enhanced machine learning capabilities.